

Como ocurre en casi todos los aspectos de nuestra vida diaria, solemos ignorar el funcionamiento detrás de las cosas que, para muchos, se han convertido en cotidianas desde tiempo atrás. Fenómenos como el lenguaje, la cultura e incluso nuestro propio comportamiento tienen motivos muchas veces desconocidos o ignorados por la mayoría, los cuales hacen y dan razón a su existencia. La ciencia y la tecnología no están exentas de éstas, si bien son concebidas en primera instancia en la mente de un pensador, no es sino hasta la práctica o implementación de tales ideas cuando realmente se definen su estructura y todos los detalles que la conforman.
Muchos hablan de cómo las matemáticas están inmiscuidas en cada aspecto de nuestra cotidianidad, sin embargo, al cuestionarnos, resulta difícil entender cómo las derivadas que se nos enseñaron en bachillerato nos son de utilidad. Incluso, no hay garantía de que un experto en cálculo infinitesimal conozca todas y cada una de las aplicaciones de la bella teoría que él mismo puede recitar, a veces, de memoria.
Las matemáticas, a diferencia de las otras ciencias, no requieren experimentación para comprobar una hipótesis, llamada en el área matemática conjetura. Además, en matemáticas, una vez que se ha probado un teorema, éste es irrefutable. En tal solidez se sustentan o apoyan diversas áreas del conocimiento. Cabe resaltar que un matemático desarrolla matemática para sustentar y desarrollar matemática, sus aportes, por lo general, no son pensados para dar solución a un problema particular en alguna otra área de la ciencia, aunque, desde ramas como la física y la economía se han planteado diversos problemas de interés para los matemáticos.
Ahora, remontémonos a finales de los años noventa del siglo XX. Un par de estudiantes de doctorado, Segei Brin y Lawrence Page, de la Universidad de Stanford, desarrollaron un algoritmo capaz de dar orden al caos que imperaba en internet en ese entonces, cuando su uso no era tan extendido como lo es hoy en día. Ellos presentaron el ahora llamado algoritmo PageRank; su objetivo: hacer un listado las páginas web, posicionando en los primeros sitios a las de mayor peso (por páginas web de mayor peso entendemos que son aquellas con más solicitudes por parte de los usuarios, entre los cuales podrían estar incluidas otras páginas web), de modo que entre los diez primeros resultados de la búsqueda se encontrase información útil. Este par de estudiantes de doctorado había desarrollado el motor de búsqueda más poderoso jamás implementado y que hoy nosotros conocemos como Google.
El nombre surge de la variación del nombre googol, con el que se designa al número 10100 (el número diez multiplicado cien veces por sí mismo); un nombre ad hoc, pues este buscador accede a cientos de miles de páginas web y las organiza, como ya hemos dicho, según su popularidad. Pero ¿cómo hace esto? Google se concibió primeramente como un grafo (figura 1), específicamente, como un grafo dirigido (figura 1).

Cada página web es representada por un nodo y cada arista representa citas entre ellas; por ejemplo, en el lado derecho de la imagen, la página A cita a la página B y es citada por las páginas B, D y E. Ahora tiene más sentido hablar sobre el peso de una página, así, podemos decir que, en nuestro ejemplo, la página A es la de mayor peso, debido a que es la página que más citas tiene. Así, podemos visualizar la web como un gráfico (o grafo) con esta serie de nodos y aristas, ya de entrada algo abstracto. Pero podemos subir un poco el nivel de abstracción, es decir, darle un enfoque un tanto más matemático.
Una de las ventajas que presentan los grafos es que pueden ser representados en forma matricial, en lo que se conoce como matriz de adyacencia del grafo. En esta matriz, cada renglón y columna representan un nodo y en cada entrada se escribe el número de veces que un nodo está conectado (o «cita») a otro. Por ejemplo, las matrices de adyacencia, M, del grafo dirigido y del no-dirigido de la figura 1 son las siguientes:

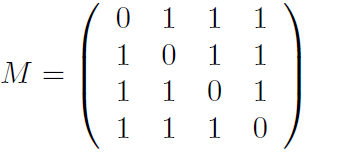
Hasta ahora, las matemáticas sólo han hecho una tenue aparición, y para ser sinceros, no ha sido tan espectacular. En sí, la matriz, hasta el punto en el que nos encontramos, no nos ha arrojado a la luz una solución para resolver nuestro problema. Es aquí en donde los estudiantes Brin y Page se auxiliaron verdaderamente en las matemáticas, específicamente en el teorema de Perron-Frobenius(TPF).
Oskar Perron, nacido en Alemania en el año de 1880, dio un resultado, en el año 1909, sobre matrices positivas que aseguraba la existencia de un eigenvector (se lee: [aiguenvector]), o vector propio, de módulo máximo y llevaba asociado un eigenvalor, o valor propio, positivo. Ferdinand George Frobenius, de origen alemán y nacido en el año 1849, generalizó el postulado de Perron a matrices irreducibles, en lo que se conoce hoy como TPF. Este teorema tiene ya más de cien años y en ese entonces era considerado demasiado abstracto para ser aplicable.
De vuelta al algoritmo, es preciso realizar un cambio en nuestro planteamiento. La principal razón por la que es necesario el cambio de criterio de asignación de peso es la pérdida de información que nos provoca nuestro primer planteamiento, pues existen páginas de mayor importancia que otras, como en nuestro ejemplo de la figura 1, B es una página relativamente importante porque es citada por A, la página más importante. Se denota por el vector x al vector de importancias de las páginas web, que esta vez determinaremos considerando estos dos aspectos en la asignación del peso de una página:
1. Número de páginas que la citan.
2. Importancia de las páginas que la citan.
Esto es, la entrada xi designa la importancia (o peso) de la página Pi (recordemos que puede ser un reglón o una columna). ¿Cómo encontramos estos valores de xi? Debido a esta asignación, es fácil conjeturar que cada entrada del vector de importancias, x, es proporcional a la suma de importancias que enlazan con ella. En el ejemplo, el peso de las páginas A, B, C, D y E estaría designado por:

Entonces, obtenemos un sistema de ecuaciones como el siguiente:
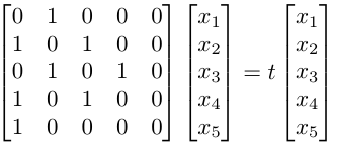
O simplemente Mx = tx (representación simbólica del sistema de ecuaciones). El objetivo es encontrar los valores de x1, x2, x3, x4 y x5.
Para fines ilustrativos, opté por tomar una matriz pequeña, que fuera capaz de mostrar el proceso de planteamiento del problema. Las dimensiones reales de este problema son casi inimaginables para una persona ajena al área de la computación, pues se manejan matrices gigantescas con varios niveles en el orden de magnitud. Pese a las ventajas que supone la representación, está lejos de ser útil en la resolución. Hay que asegurar primero que se cumplan las hipótesis del teorema, para luego implementarlo.
Gracias al TPF, Brin y Page tuvieron la certeza de la existencia de lo que buscaban, en términos matemáticos, un eigenvector; no obstante, el TPF no dice nada sobre cómo encontrarlo o cuál es ese vector. A partir de este punto, sólo bastaba con hacer los cálculos, que resultan un poco más complejos y requieren de un conocimiento más técnico de la terminología y las técnicas apropiadas. En las referencias se podrá encontrar información más completa sobre cómo se resolvió el problema en aquél entonces, así como otras aplicaciones que tiene el TPF en otras áreas del conocimiento.
El teorema de Perron-Frobenius es el vivo ejemplo de cuán adelantadas están las matemáticas a nuestra realidad actual. Además, cada vez hay menos teoremas y postulados inaplicables. Este teorema es la muestra de cómo los hilos de la abstracción nos unen a todos.
Glosario
- Nodo: punto que simboliza un elemento del conjunto estudiado.
- Arista: segmento de recta que simboliza el enlace entre nodos.
- Eigenvector: vector que al ser multiplicada por la matriz, M, de interés devuelve como resultado el mismo vector multiplicado por una constante t, ie Mx = tx.
- Módulo: longitud de un vector.
- Eigenvalor: nombre que se le da a la constante t.
Referencias
- P. Fernández. El Secreto de Google y el Álgebra Lineal. Universidad Autónoma de Madrid, 2004.
- A. Inés. El teorema de Perron-Frobenius y su aplicación en el algoritmo de búsqueda de Google. Facultad de Ciencias, Universidad de la Rioja, 2015.
- A. Barbasi. Linked: The new Science of Networks. Plume, 2003.

Un comentario en “El teorema que nos une a todos”